
Tag: Structured Contents
Blog articles related to API features and announcements specific to our beta Structured Contents initiative.
← Back to Blog: Latest Articles
-
Access Wikipedia’s most valuable tables as structured JSON with the new Parsed Tables feature from Wikimedia Enterprise. Instantly convert complex tables into clean, machine-readable data without scraping. Enhance your AI, search, and knowledge graph projects with reliable, human-curated facts that were previously locked away in HTML and wikitext.

-
Explore Wikipedia content in a clean, structured format with our new beta dataset on Kaggle. Built from our Snapshot API using the Structured Contents beta, it’s ideal for data science, ML training, and experimentation.

-
The latest API release boosts Wikipedia data integration with parsed references in JSON and two quality scoring models – Reference Need and Reference Risk. These enhancements streamline citation access and improve content reliability for developers.

-
We’re releasing an early beta dataset on Hugging Face, offering structured content from English and French Wikipedia. This machine-readable dataset, derived from our Snapshot API’s new Structured Contents beta, opens up new possibilities for AI and machine learning applications.

-
Snapshot API now includes a beta Structured Contents endpoint, offering bulk access to parsed Wikipedia data for testing partners.
-
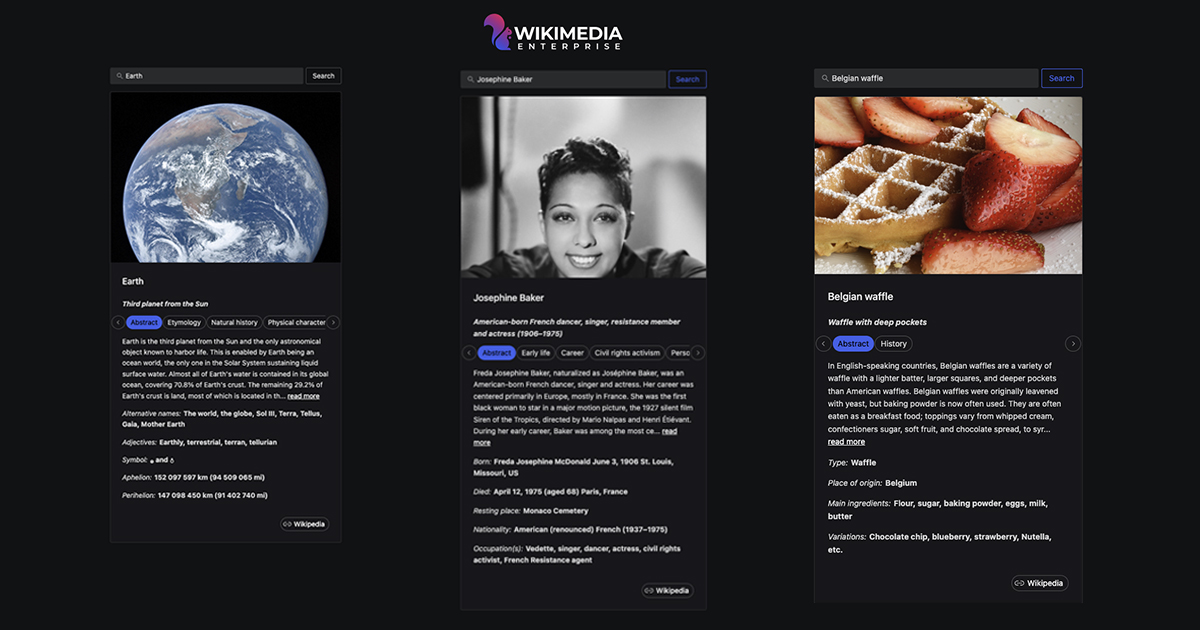
In this engineering tutorial, we show a simple way to build a working knowledge panel pulling pre-parsed content from Wikipedia articles using Wikimedia Enterprise API Structured Contents endpoint.
-
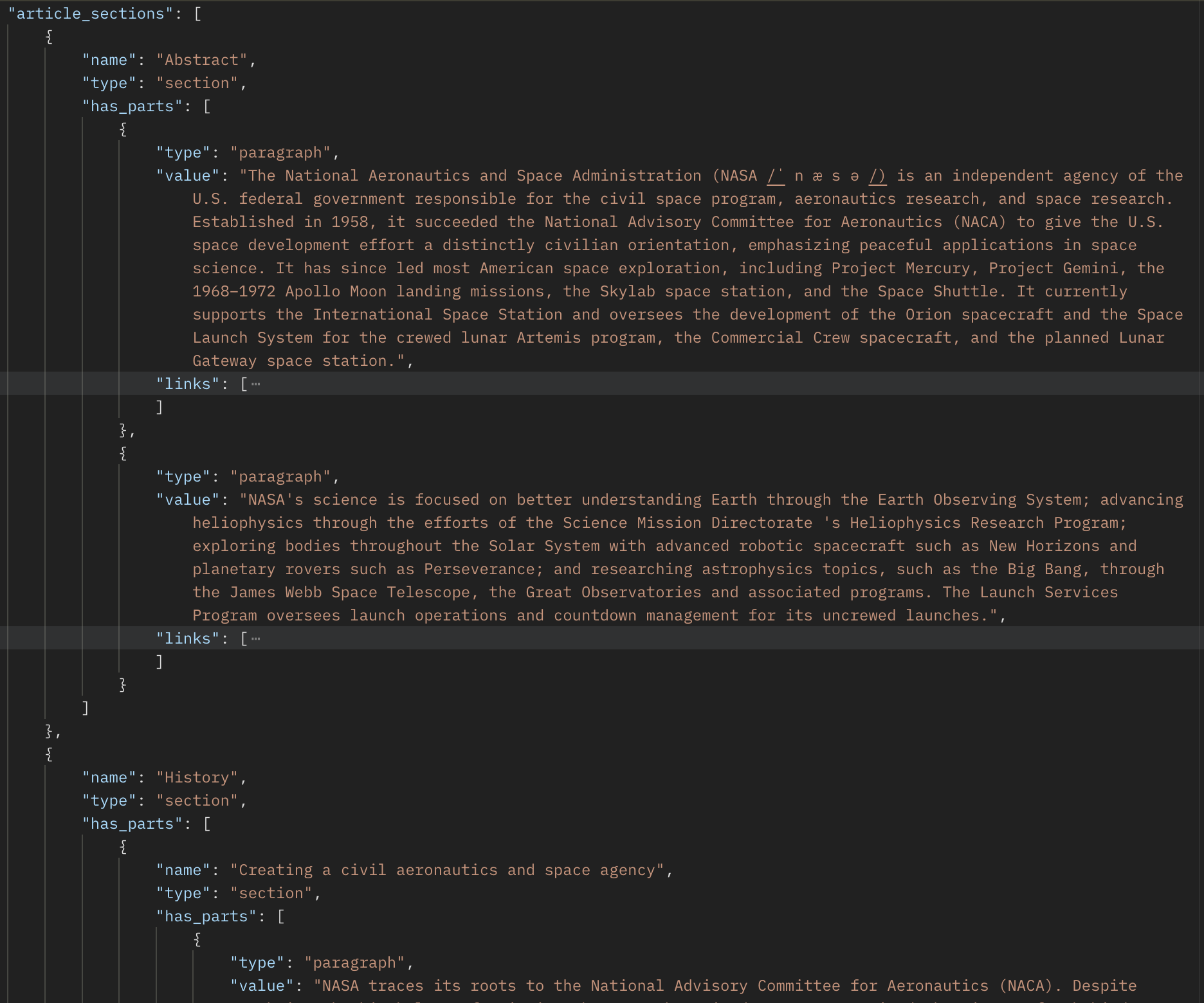
We’ve expanded the data available in our On-Demand Structured Contents endpoint by introducing two significant features: Article Body Sections and short Descriptions.
-
We’ve heard all your requests for a more machine-readable API for Wikimedia data. We are announcing a new Structured Contents endpoint with the fully parsed contents of Wikipedia article Infoboxes in JSON! Jump into the article to read about it and get started.